
Evaluation Sets
In the Evaluation Sets tab, you can create specific sets of prompts that simulate user interactions and provide expected SQL outputs alongside these prompts. This allows for a direct comparison to see how accurately the AI converts natural language into database queries. To create an Evaluation Set:- Open a Domain and click on the Evaluation tab.
- Navigate to the Evaluation Sets Sub-tab.
- Click Add Evaluation.
-
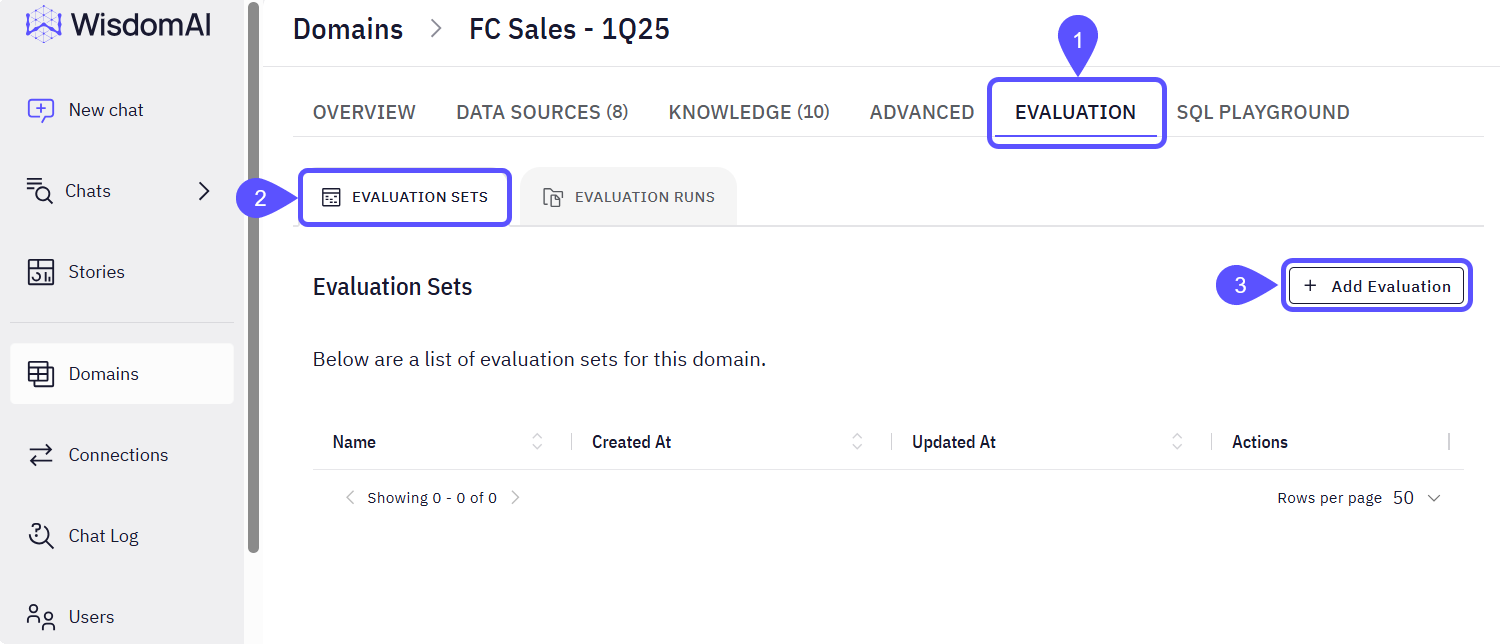
Fill out the Add Evaluation Form, providing a set Name and an array of prompts in JSON format, optionally including the expected SQL.
The array you provide defines how many conversations will be created. Each top-level element in the array represents a conversation:✔ If it’s a string or an object → You get a single-message conversation
✔ If it’s an array → You create a multi-message conversationFor example, this input:
["prompt1", ["prompt2.1", "prompt2.2"], "prompt3"]
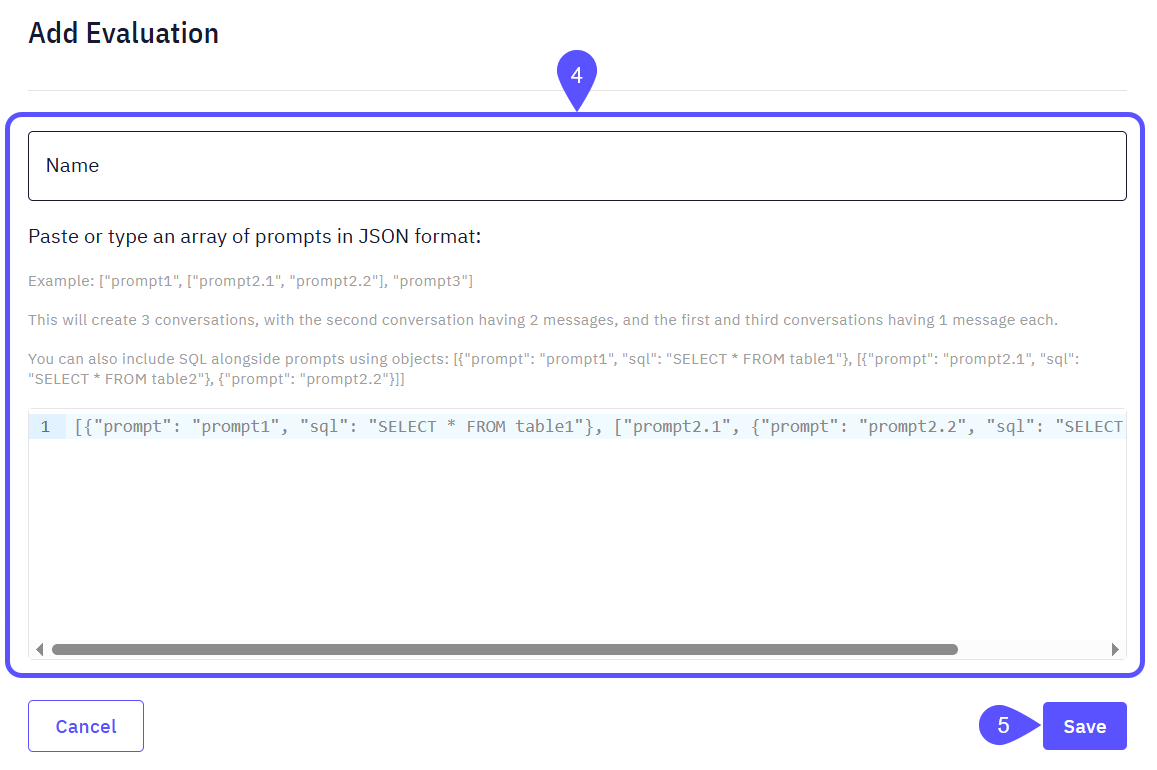
creates 3 conversations: the first and third with one message each, and the second with two messages.You can structure the arrays in any way, mixing single and multi-message conversations as required. - Click on Save. The new Evaluation set will appear listed.
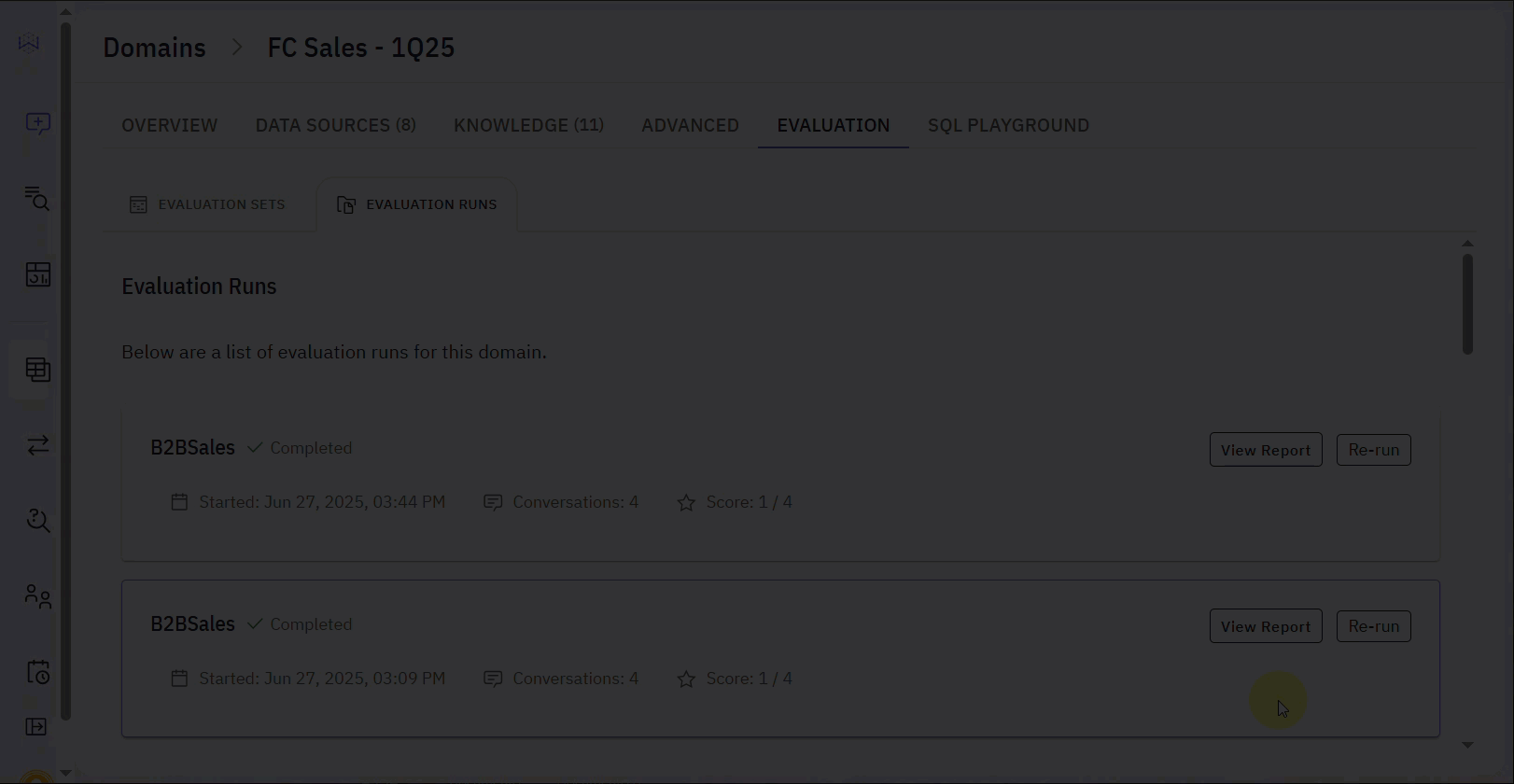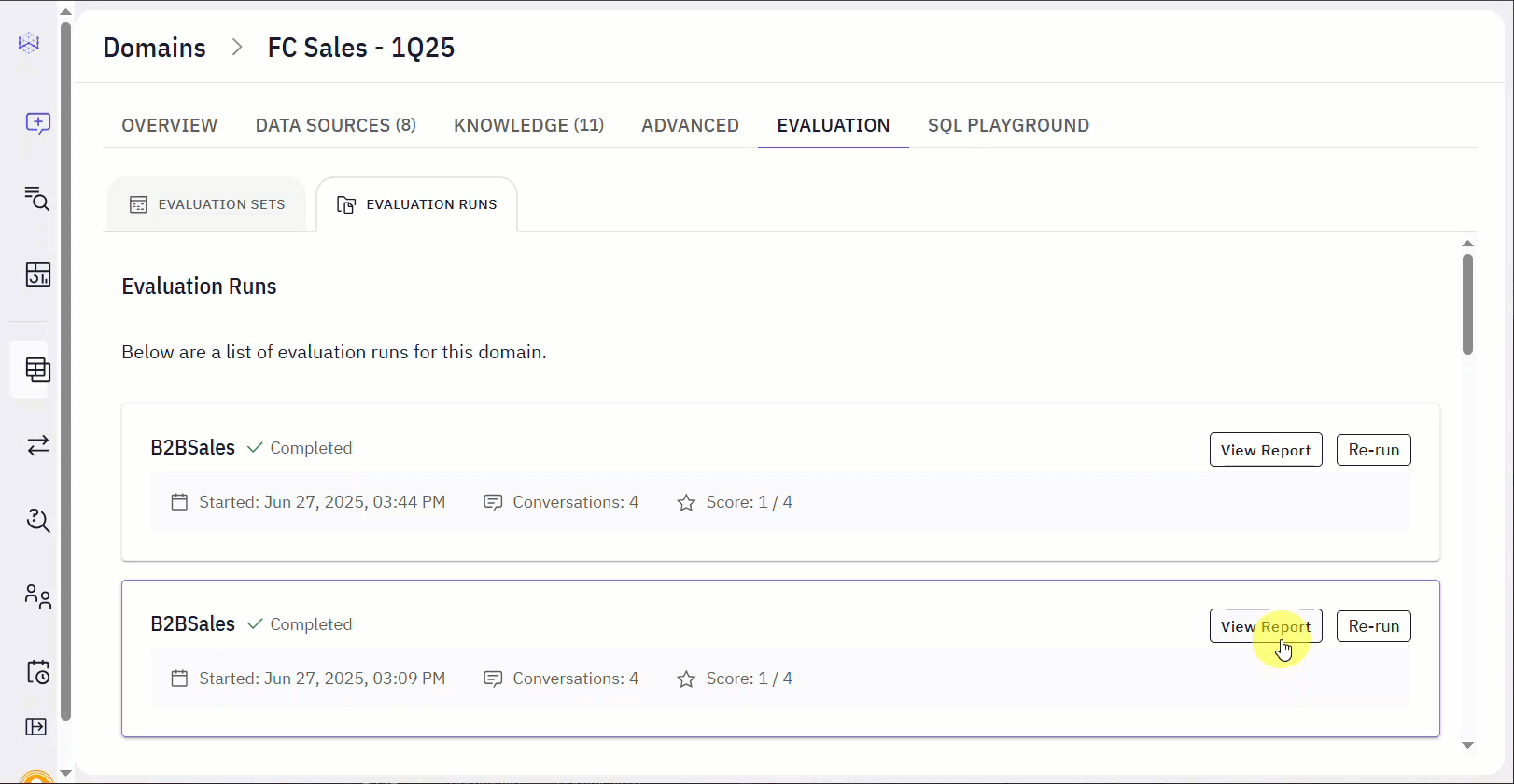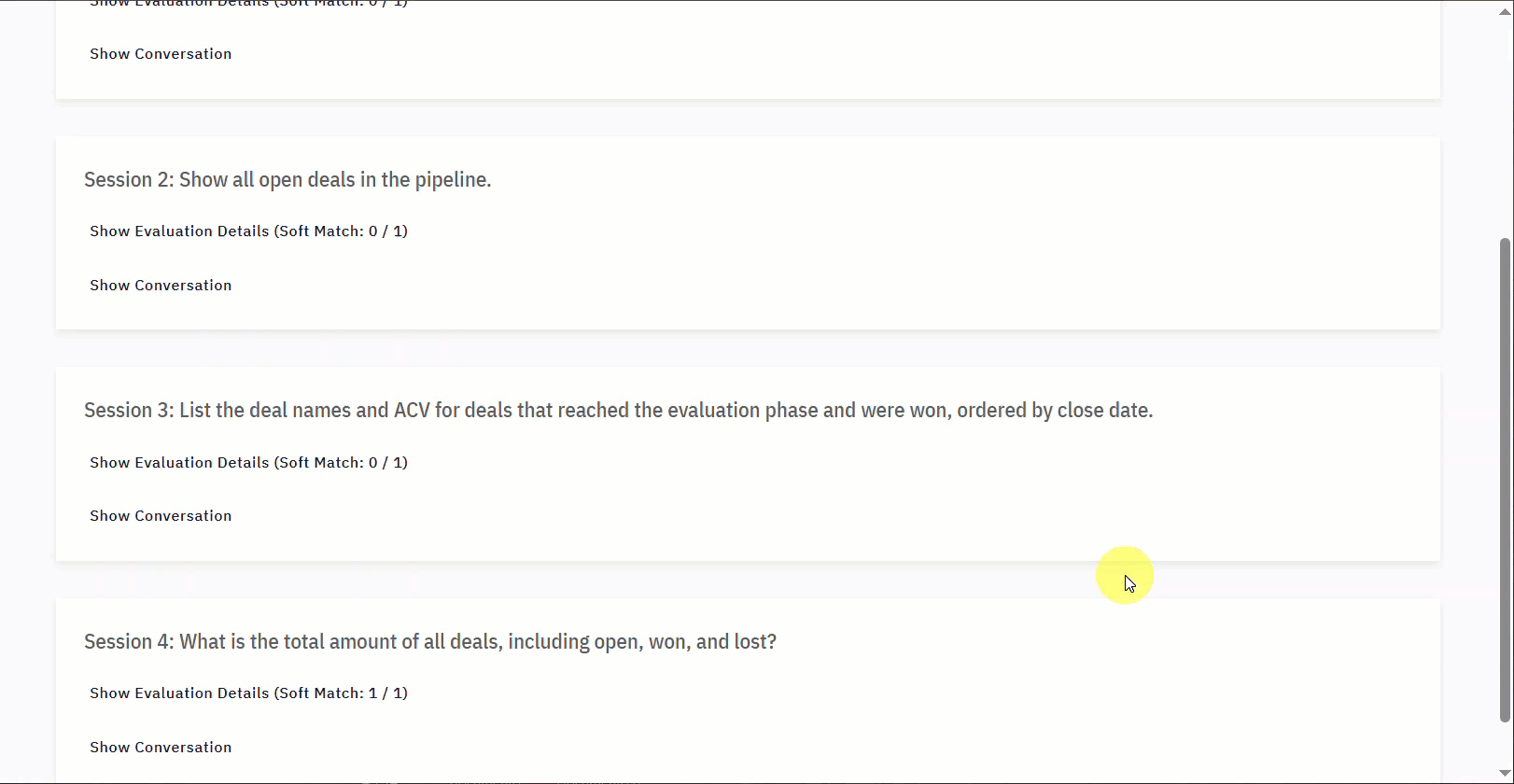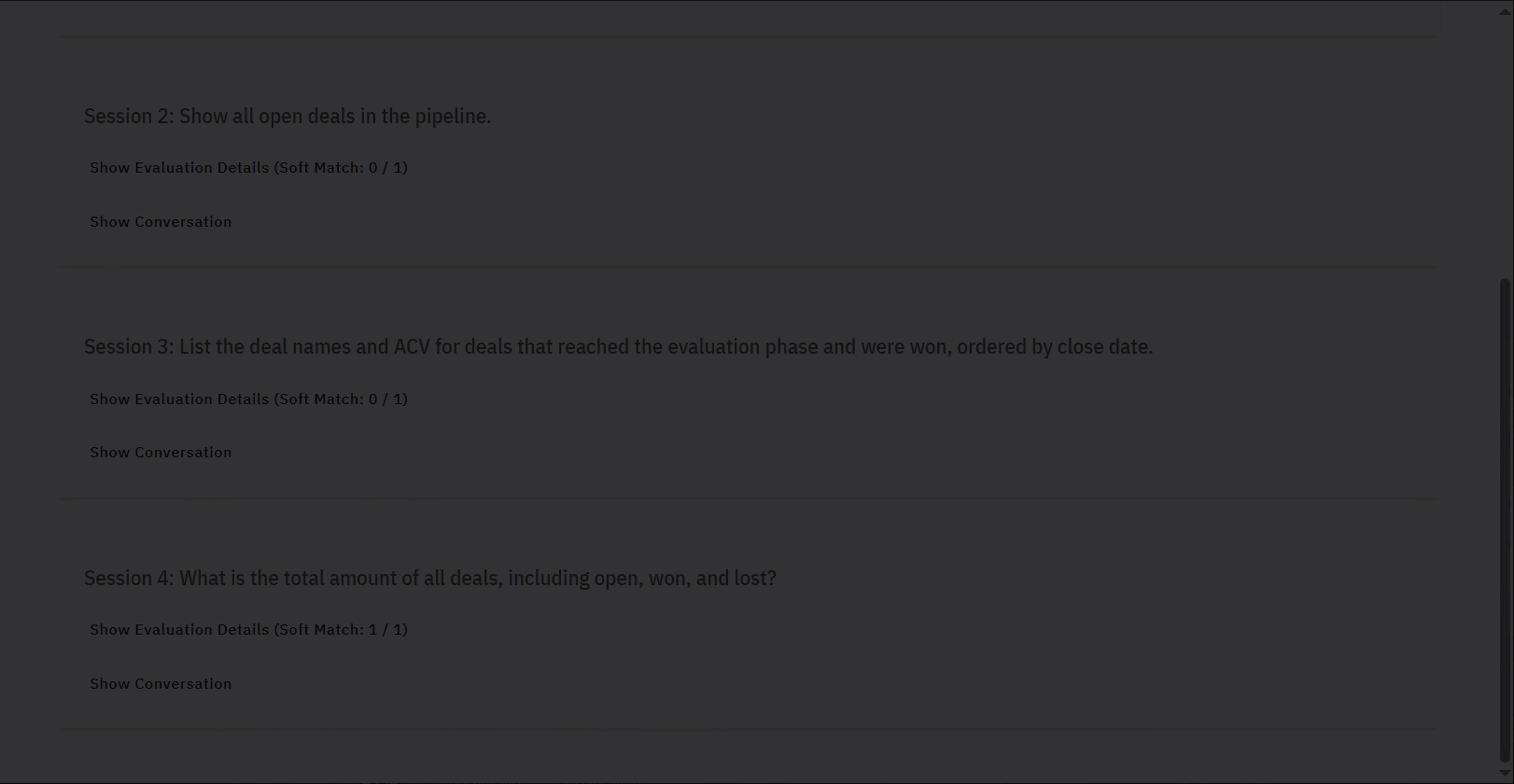
Evaluation Runs
Evaluation Runs are where the AI processes your defined Evaluation Sets. After running these evaluations, you can review the results to identify areas for improvement. To run an Evaluation, go to the Evaluations Set tab, select an evaluation, and click on Run. You will see the results in the Evaluation Runs tab.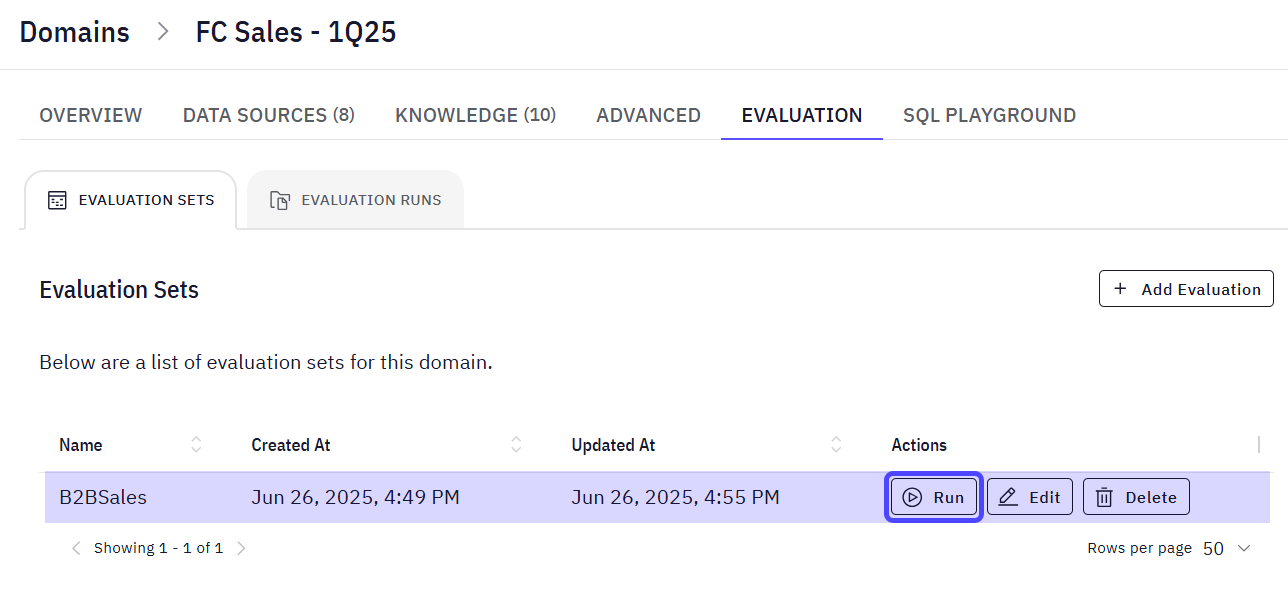
Evaluation Run Indicators
Evaluation Run Indicators provide a concise overview of the Run’s progress and outcome. These indicators offer immediate feedback on the Evaluation’s status and score, detailing how well the AI’s generated responses matched the expected results. They are:- Status: Signals its progress or completion.
- Running: The evaluation run is currently in progress.
- Completed: The evaluation run has finished successfully.
- Score: Reflects the result of the completed Evaluation. It tells you how many conversations passed based on the predefined evaluation criteria (i.e., Prompt + Expected SQL result added in the Evaluation set modal).
The Score evaluation criteria refer to how much the generated answer matches the expected SQL result defined previously.
Evaluation Run Report
When you click the View Report option, you will see comprehensive details about how the evaluation run performed. Here’s a breakdown of the information you’ll find:- View Domain: A link that allows you to navigate to the specific domain that was evaluated.
- Soft Match: This Score indicates the overall performance of the Evaluation. It shows how many of the evaluation criteria were successfully met out of the total. It is named as Soft Match since results may be considered a match even if they are not the same as the expected (provided) SQL.
- Individual Session Details: The report organizes the evaluation results by individual sessions or queries (e.g., Session 1, Session 2).
- Session Title: This states the query or task that was evaluated for that particular session (e.g., “Calculate total revenue for closed won opportunities using ACV.”).
- Evaluation Details: This expandable section provides specific insights into the session’s outcome. The core components are detailed in the table below.
| Component | Description |
|---|---|
| Prompt | The specific input prompt that was used for the session. |
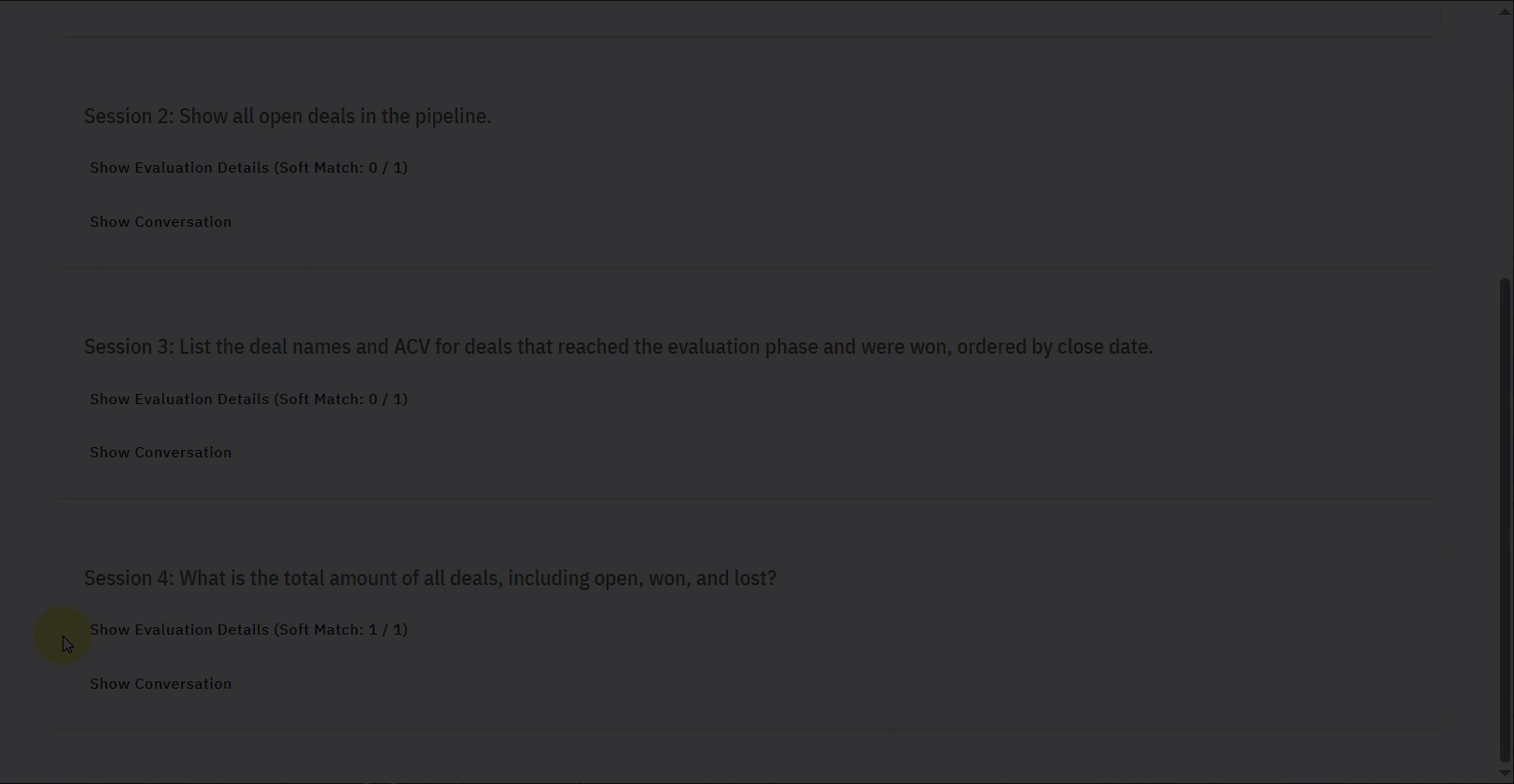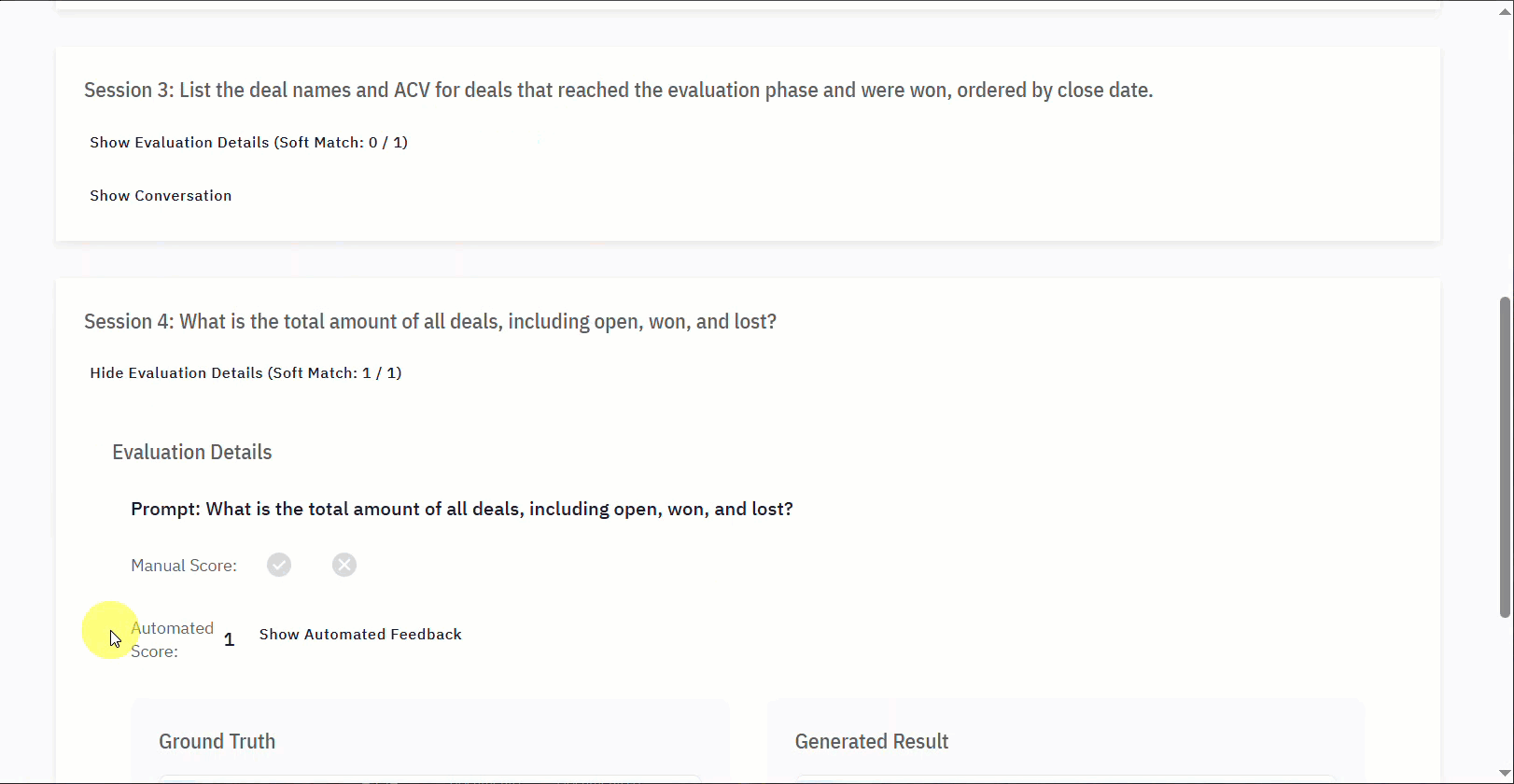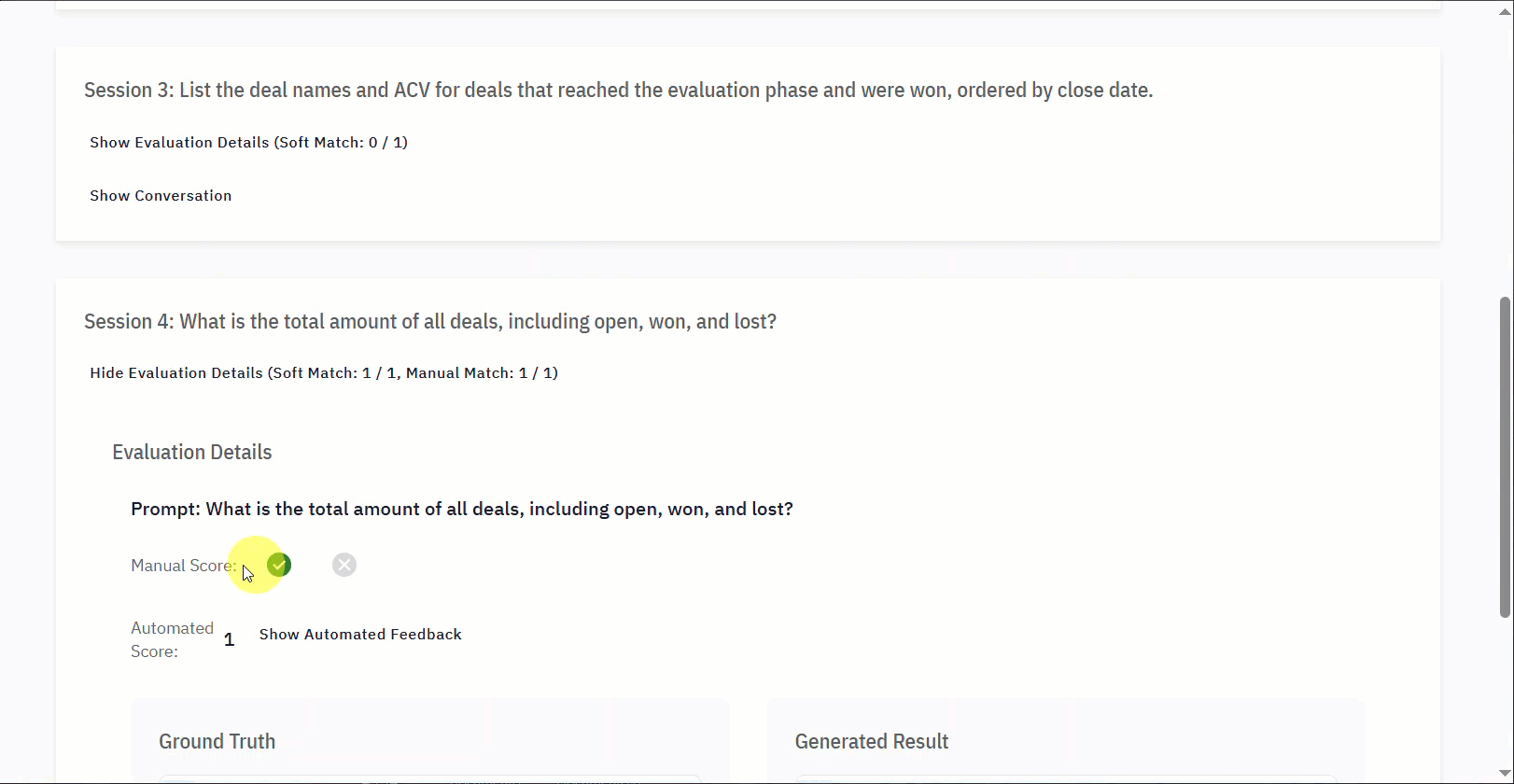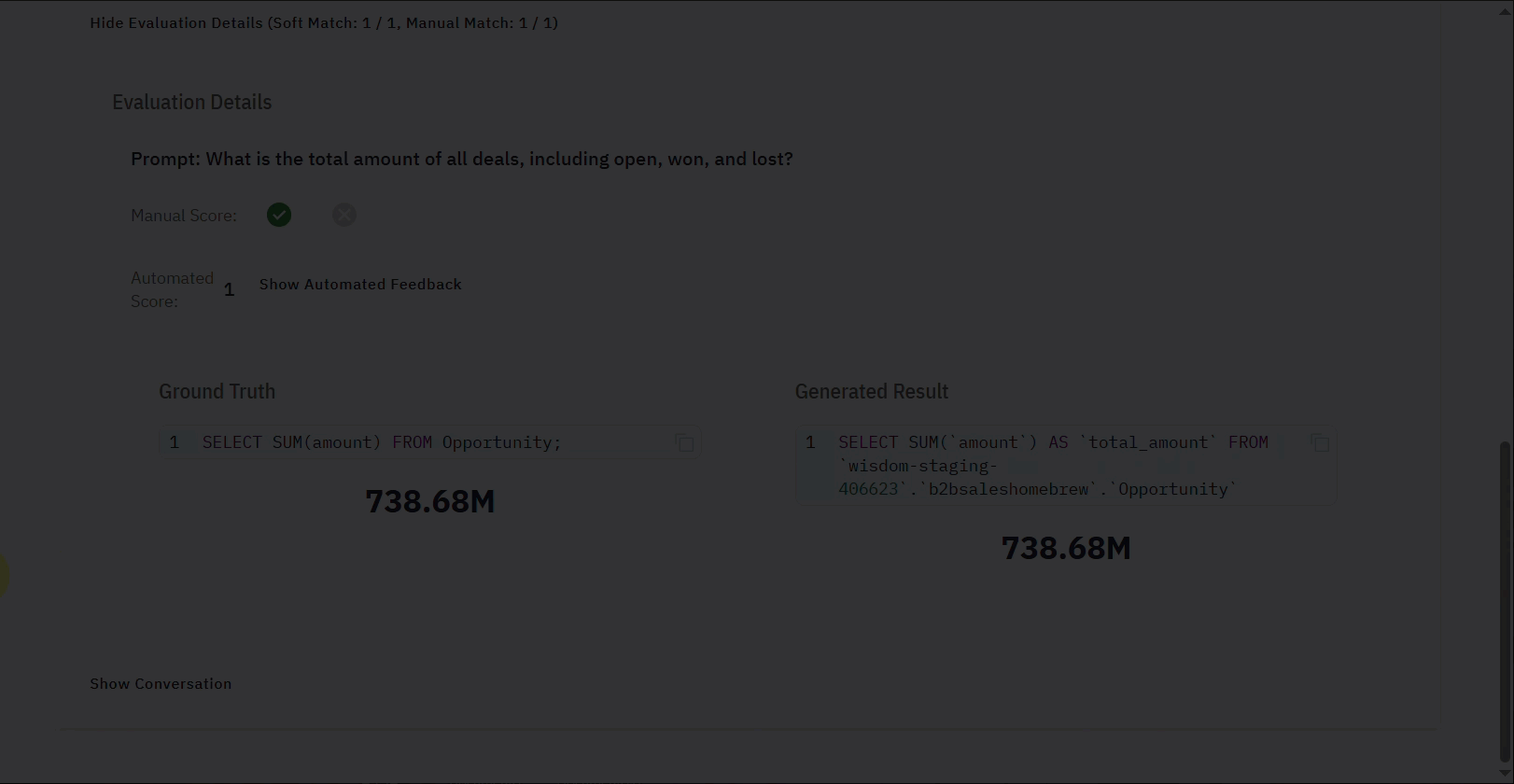
| Manual Score | An option for you to manually score the Evaluation (✅ or ❌), which overrides the automated score. |
| Automated Score | The system automatically assigns the score. This corresponds to the Soft Match. |
| Ground Truth | The expected or correct outcome, typically the ideal SQL query (SELECT SUM(amount) FROM Opportunity). |
| Generated Result | The output produced by the system, including the generated SQL query and the final result (e.g., "$137.55M"). |
Providing an incorrect SQL code will lead to a syntax or semantic error. The system will display a red message detailing the nature of the error, often including the location within the query where the problem occurred, to aid in correction.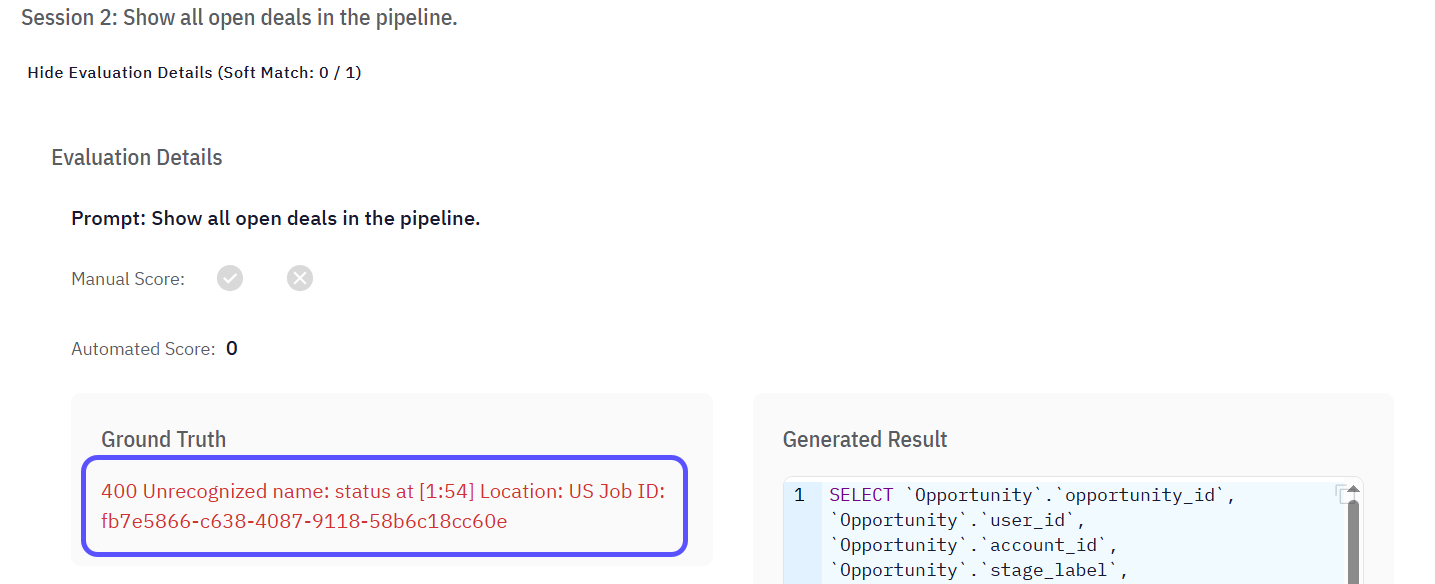
- Conversation: You can expand this section to review the entire conversational exchange related to that specific session. This includes:
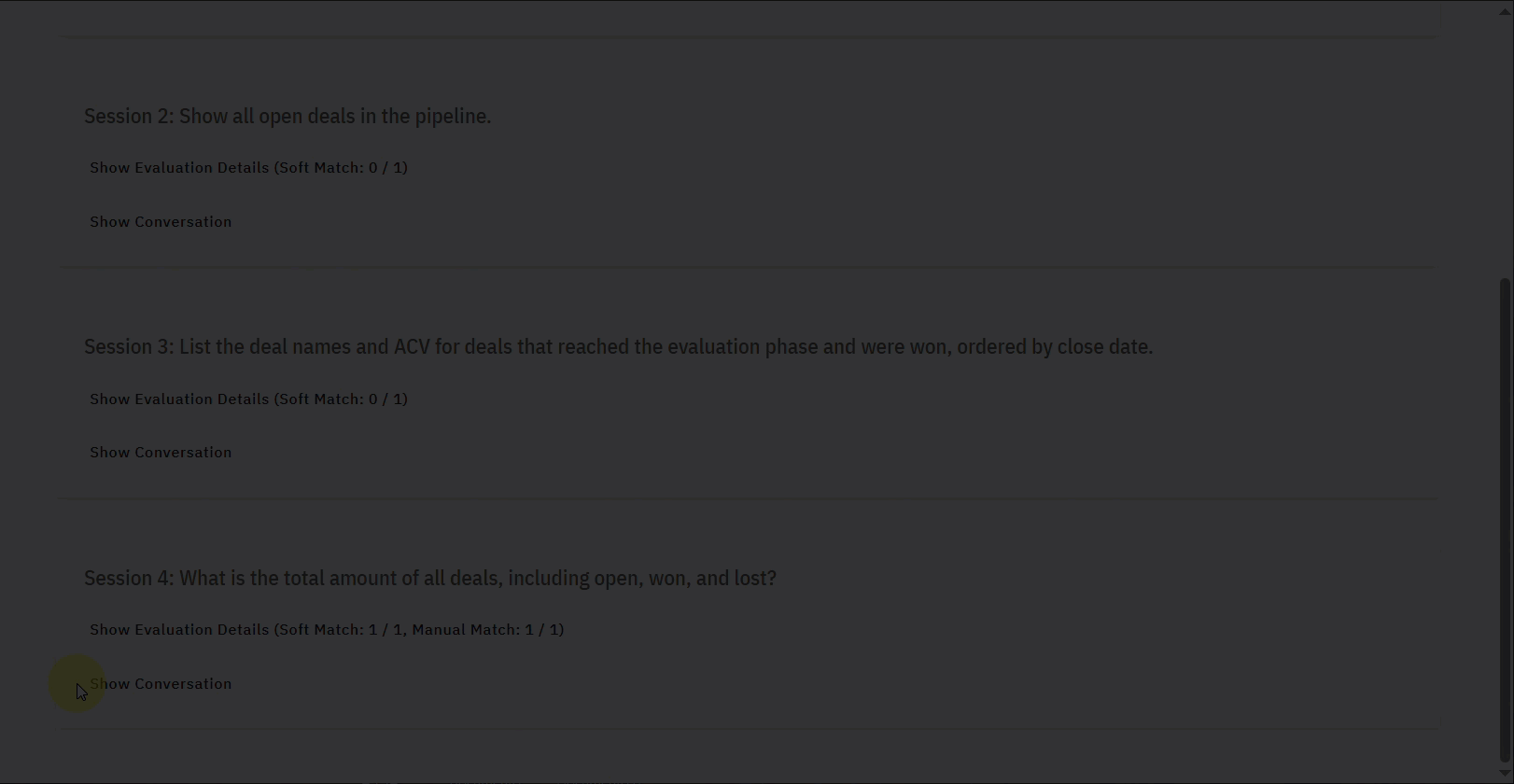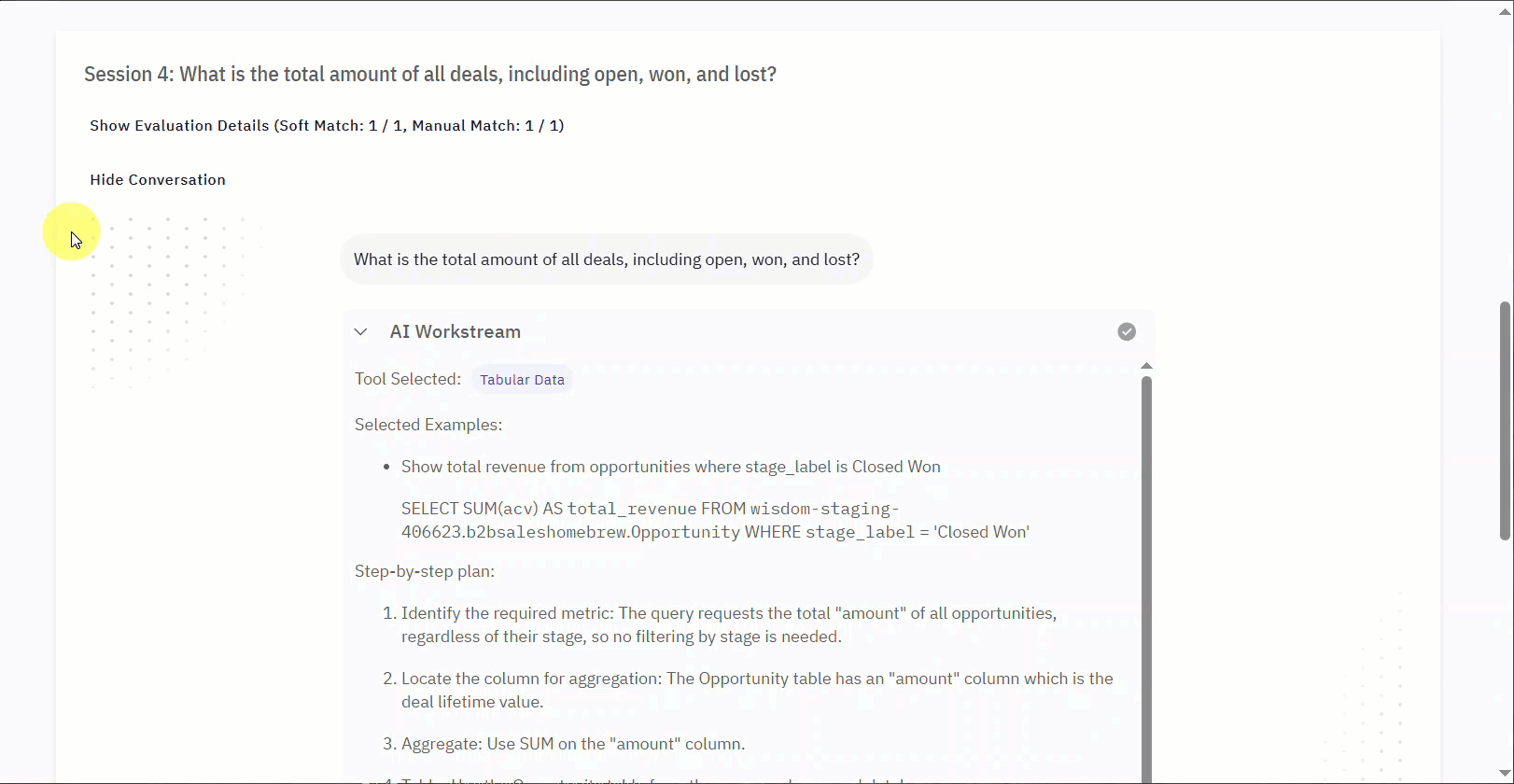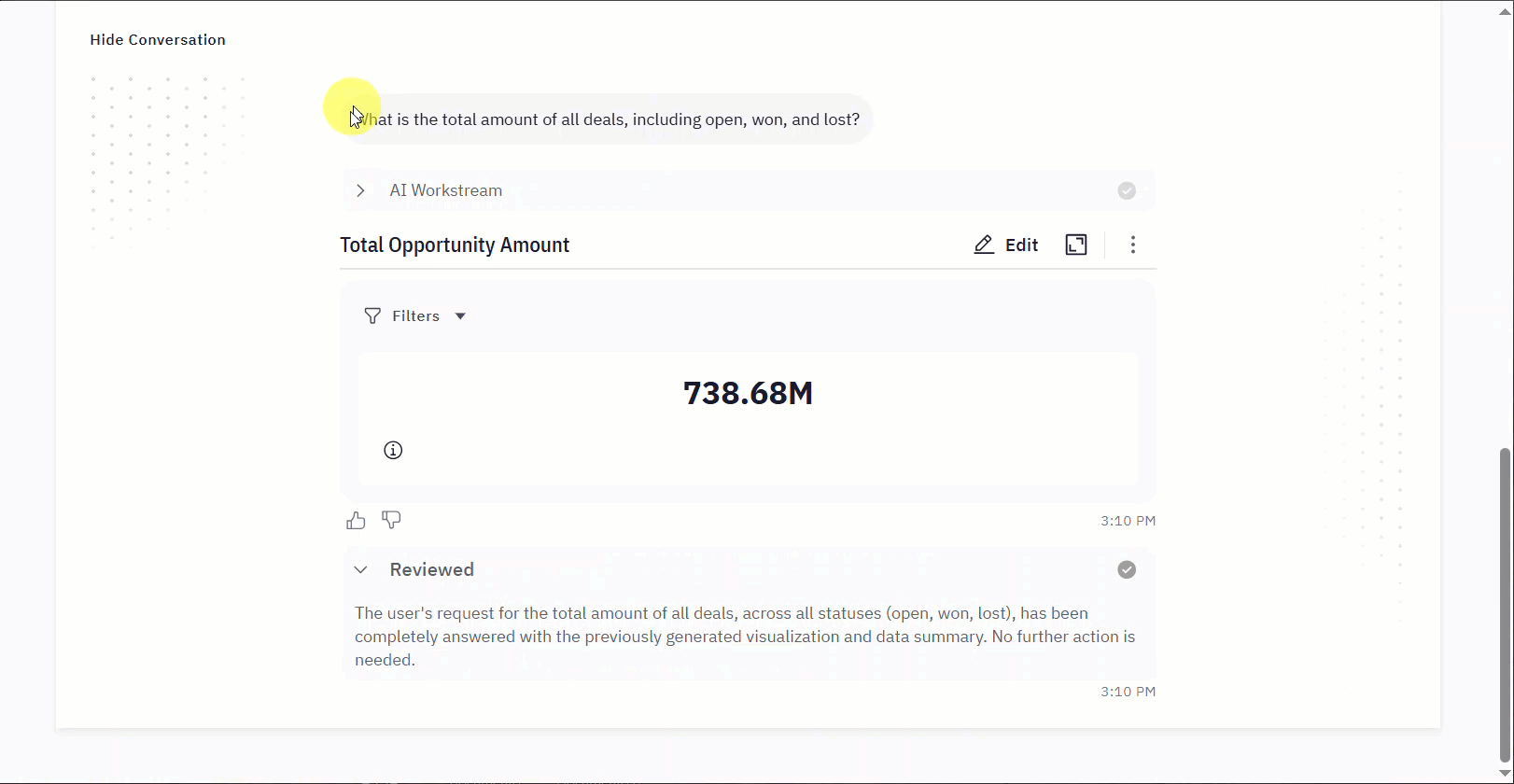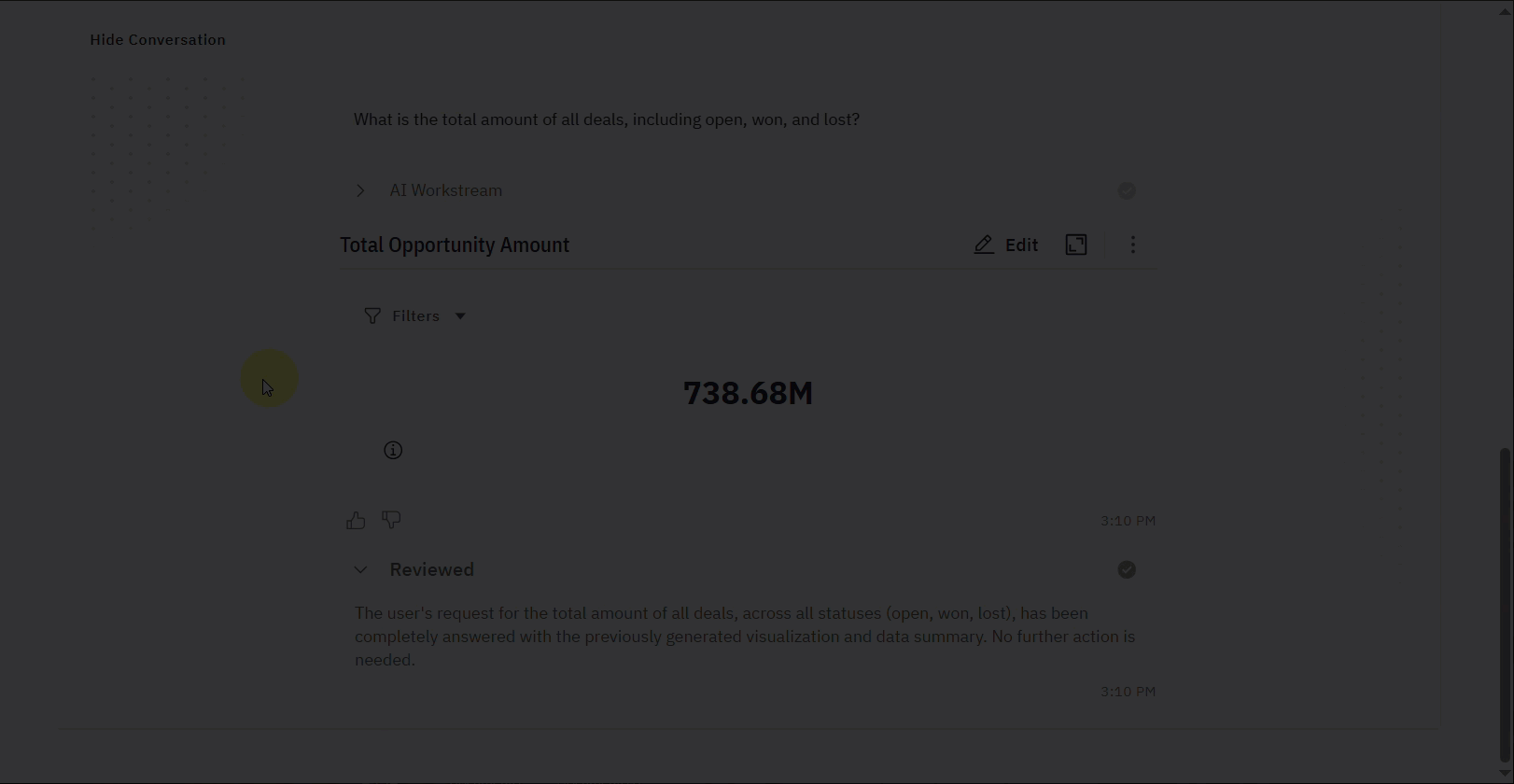
- AI Workstream: Offers a look into the AI’s process, showing the tool it selected, the examples it referenced, and the step-by-step plan it followed to generate the response.
- Reviewed Status: Confirms whether the response has been reviewed and summarizes the outcome (e.g., “The user received a complete response… so no further action or information is needed.”).
Next Steps
Configure Domains
Manage and customize your data domains to refine context and improve query results.
Auditing
Organize insights by tagging chats, navigating history, and sharing vetted answers with your team.
Basic Tutorial: Connect and Test
Walk through the initial setup to connect a data source and run your first query.
Advanced Data Modeling
Define relationships and context in your data to enable more powerful analysis.